Challenge:
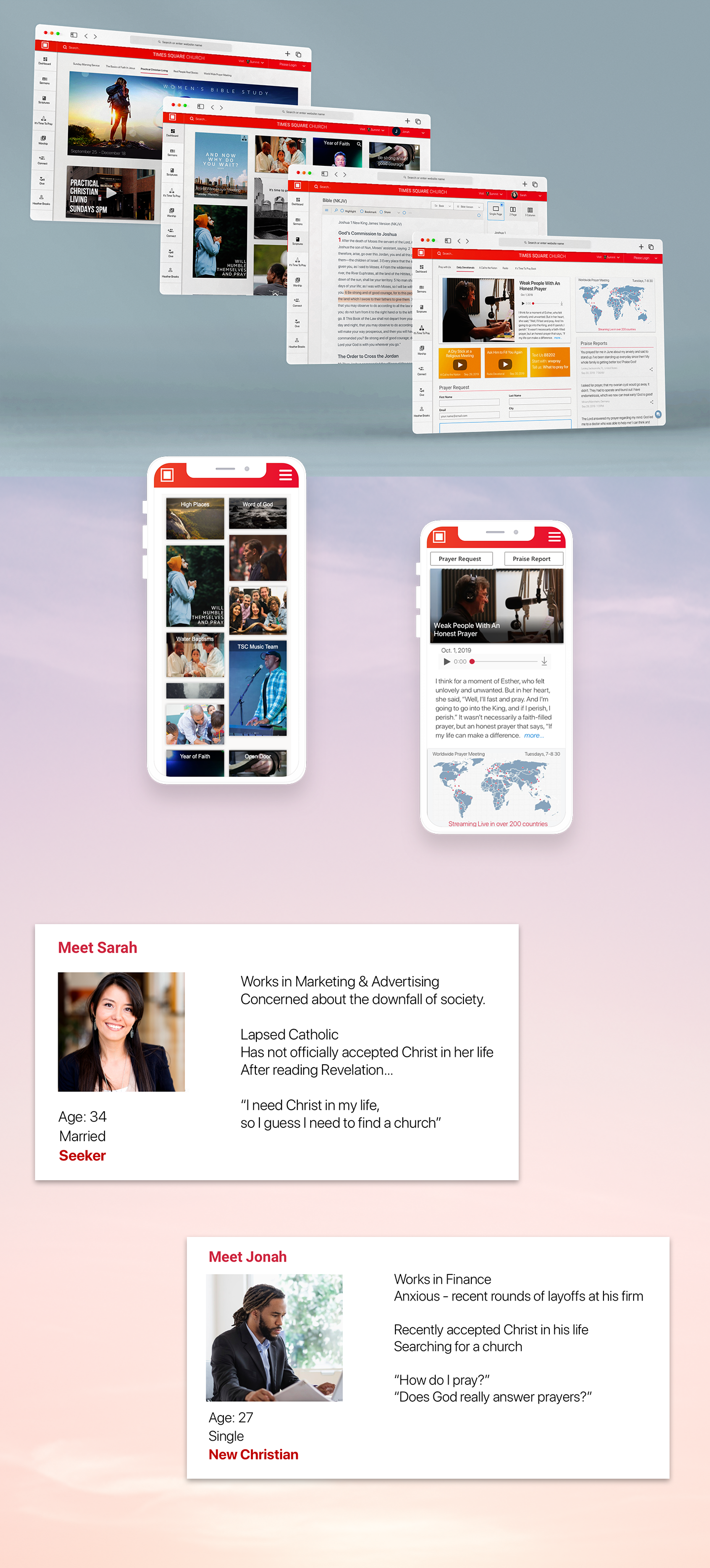
With over 4,000 recorded sermons in both audio and video format, spanning nearly 40 years, a repository of media files was left un-searchable by the typical visitor to TSC.NYC
Usage tracking, along with user feedback, suggests that viewing and searching for sermons is the top observed activity on the site. User interviews also reveal that the top complaint is the inability to find specific sermons. Links are often passed around but even the titles are not enough for users to find what they are looking for.
Like most media repositories, TSC's media is stored in a file structure and managed using fundamental attributes such as date, title, speaker, and the occasional description. Furthermore, titles and descriptions are often not enough to describe the content of a sermon or lesson.
How do we help user’s find what they are looking for or interested in?
How can we categorize user interest?
How do we better describe what’s in a sermon?
How do we connect the User’s Interest with the proper content?
Usage tracking, along with user feedback, suggests that viewing and searching for sermons is the top observed activity on the site. User interviews also reveal that the top complaint is the inability to find specific sermons. Links are often passed around but even the titles are not enough for users to find what they are looking for.
Like most media repositories, TSC's media is stored in a file structure and managed using fundamental attributes such as date, title, speaker, and the occasional description. Furthermore, titles and descriptions are often not enough to describe the content of a sermon or lesson.
How do we help user’s find what they are looking for or interested in?
How can we categorize user interest?
How do we better describe what’s in a sermon?
How do we connect the User’s Interest with the proper content?
Approach:
The goal of the Digital Ark project is to intelligently offer recommended content to users based on an initial onboarding and refined by their ongoing browsing behavior.
First, we need to understand our content.
We use IBM Watson Video Enrichment. By ingesting media files and transcripts to Watson Video Enrichment, we can unlock the keywords and themes of the sermons making them searchable. Watson will also track the occurrence, relevance and location for these keywords and themes. We also trained Watson with a series of Corpus file to better understand the organization’s lingo.
We then use IBM Watson Studio and Watson Machine Learning to develop a recommendation engine to curate content for clusters (or cohorts) of users based on their viewing history.
Cohorts are in effect dynamic user Personas that continually evolve. This makes the content recommendation respond to changes in the user’s interest.
First, we need to understand our content.
We use IBM Watson Video Enrichment. By ingesting media files and transcripts to Watson Video Enrichment, we can unlock the keywords and themes of the sermons making them searchable. Watson will also track the occurrence, relevance and location for these keywords and themes. We also trained Watson with a series of Corpus file to better understand the organization’s lingo.
We then use IBM Watson Studio and Watson Machine Learning to develop a recommendation engine to curate content for clusters (or cohorts) of users based on their viewing history.
Cohorts are in effect dynamic user Personas that continually evolve. This makes the content recommendation respond to changes in the user’s interest.
From: Manual Media Manager form
To: IBM Watson Video Enrichment